爬虫框架Scrapy
异步处理框架,可配置和可扩展程度非常高高,python中使用最广泛的爬虫框架
详细
Scrapy安装镜像(Anaconda Prompt安装命令)
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/conda config --set show_channel_urls yesconda install Scrapy
Ubuntu安装
sudo apt_get install libssl-devsudo apt_get install libffi-devsudo apt_get install build-essentialsudo apt_get install python3-devsudo apt_get install liblxml2sudo apt_get install liblxml2-devsudo apt_get install libxslt1-devsudo apt_get install zlib1g-dev
升级pyasn1sido pip3 install pysan1==0.4.4sudo pip3 install Scrapy
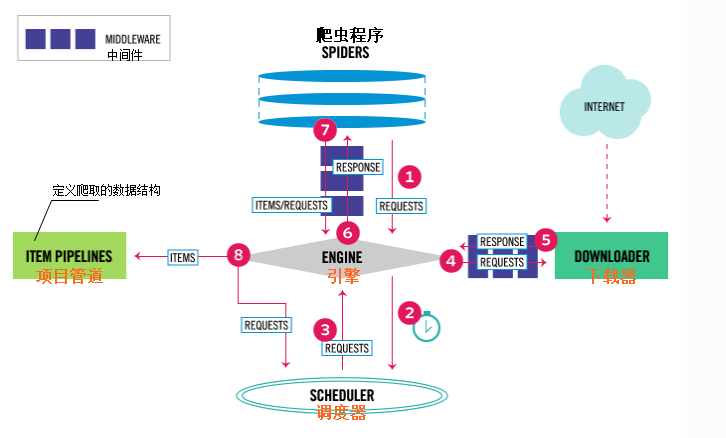
项目步骤
- 新建项目
scrapy startproject 项目名 - 明确目标
items.py - 制作爬虫程序
scrapy genspider 文件名 域名 - 数据处理
pipelines.py - 运行爬虫程序
scrapy crawl 文件名选择在编辑器运行,创建.py文件,内容如下.直接运行该文件.
from scrapy import cmdline
cmdline.execute(‘scrapy crawl 文件名’.split())
例子:
终端命令cd /jent/project/spider/spider_13scrapy startproject Baidu
out:
New Scrapy project ‘Baidu’, using template directory ‘/usr/local/lib/python2.7/dist-packages/scrapy/templates/project’, created in:
/home/tarena/jent/project/spider/spider_13/Baidu
You can start your first spider with:
cd Baidu
scrapy genspider example example.com
cd Baiduscrapy genspider baidu www.baidu.com
out:
Created spider ‘baidu’ using template ‘basic’ in module:
Baidu.spiders.baidu
打开项目目录下的baidu下的settings.py文件
更改ROBOTSTXT_OBEY = False
如果你想爬的内容更广泛,那么不要去遵守协议.不过这并不是一个好的职业道德行为.
项目文件
项目目录
Baidu
├── Baidu # 项目目录
│ ├── __init__.py
│ ├── __init__.pyc
│ ├── items.py # 定义数据结构
│ ├── middlewares.py
│ ├── pipelines.py # 管道文件
│ ├── settings.py # 定义全局配置
│ ├── settings.pyc
│ └── spiders
│ ├── baidu.py # 爬虫文件
│ ├── __init__.py
│ └── __init__.pyc
└── scrapy.cfgsetting.py配置
- 遵守ROBOX协议
ROBOTSTXT_OBEY = False - 设置并发数量
CONCURRENT_REQUESTS = 32 - 下载延迟时间
DOWNLOAD_DELAY = 1 - 请求头
DEFAULT_REQUEST_HEADERS = {} - 项目管道
ITEM_PIPELINES = {‘Baidu.pipelines.BaiduPipeline’: 300,}
- 遵守ROBOX协议
博主个人能力有限,错误在所难免.
如发现错误请不要吝啬,发邮件给博主更正内容,在此提前鸣谢.
Email: JentChang@163.com (来信请注明文章标题,如果附带链接就更方便了)
你也可以在下方的留言板留下你宝贵的意见.



