动态加载网站数据抓取
滚动鼠标滑轮时加载的内容抓取
浏览器F12 Network->QueryStringParameters
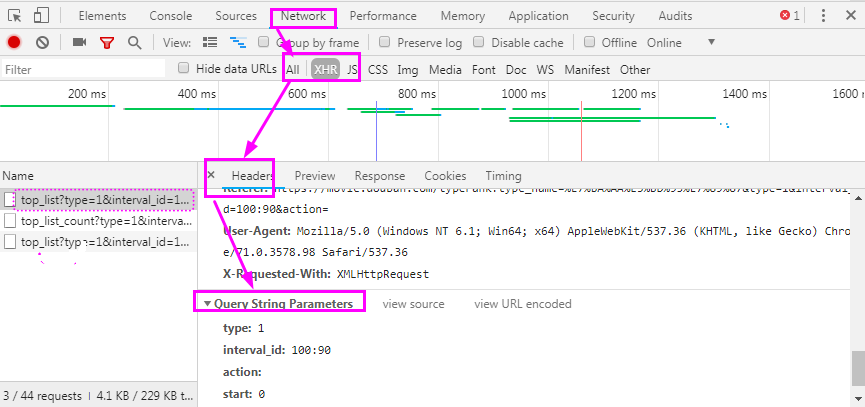
豆瓣电影的抓取
import requests
import pymysql
import json
import time
class DoubanSpider(object):
def __init__(self):
self.url = 'https://movie.douban.com/j/chart/top_list?'
# type=1&interval_id=100%3A90&action=&start=100&limit=20
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"}
# 数据库对象
self.db = pymysql.connect(
'localhost', 'root', '123456', 'doubandb', charset='utf8'
)
# 游标对象
self.cursor = self.db.cursor()
def getPage(self, params):
res = requests.get(self.url, params=params, headers=self.headers)
res.encoding = 'utf-8'
html = res.text
self.parsePage(html)
def parsePage(self, html):
# 把json格式的响应内容转为pythn数据类型
hList = json.loads(html)
# hList [{movie_1}, {movie_2}, ...]
for h in hList:
name = h['title']
score = h['score']
actors = h['actors']
L = [name, float(score.strip()), ', '.join(actors)]
self.writeMysql(L)
def writeMysql(self, L):
ins = 'insert into film(name, score, actors) values(%s, %s, %s)'
self.cursor.execute(ins, L)
self.db.commit()
def workOn(self):
num = input('爬取电影数量 >>>')
params = {
'type': '1',
'interval_id': '100:90',
'action': '',
'start': '0',
'limit': num
}
self.getPage(params)
if __name__ == "__main__":
start = time.time()
spider = DoubanSpider()
spider.workOn()
end = time.time()
print('successful within ___%.2f___' % (end - start))
# create database doubandb charset=utf8;
# use doubandb;
# create table film(
# id int primary key auto_increment,
# name varchar(50),
# score float(4,2),
# actors varchar(300)
# )charset=utf8;
# alter table film modify actors varchar(600);
博主个人能力有限,错误在所难免.
如发现错误请不要吝啬,发邮件给博主更正内容,在此提前鸣谢.
Email: JentChang@163.com (来信请注明文章标题,如果附带链接就更方便了)
你也可以在下方的留言板留下你宝贵的意见.


