多线程爬取
- 队列
from multiprocessing import Queue
put()
get() (get_nowait() => get(False))
线程创建
from threding import Thread
t = Thread(target=函数名)
t.start()
t.join()
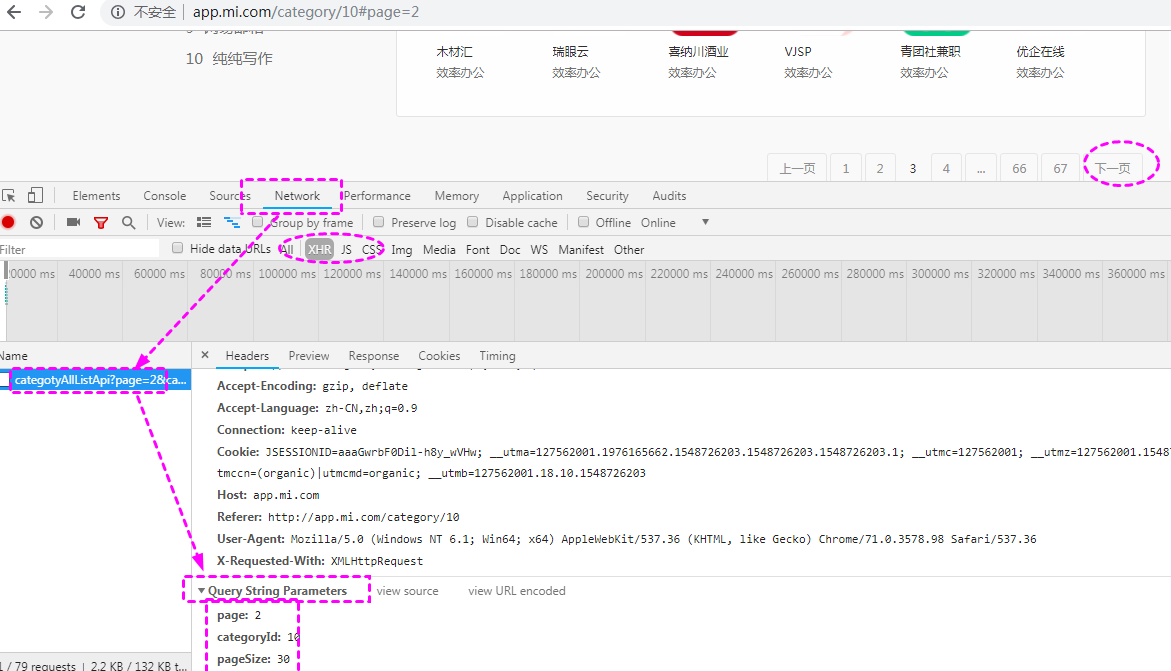
小米应用商店
小米应用商店应用分类 抓取:应用名称,应用链接
http://app.mi.com/categotyAllListApi?page=2&categoryId=10&pageSize=30
F12 -> QueryString
page: xx
categoryId: 10
pageSize: 30
代码
import requests
from multiprocessing import Queue
from threading import Thread
import json
import urllib.parse
import time
class MiSpider(object):
def __init__(self):
self.baseurl = 'http://app.mi.com/categotyAllListApi?'
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# URL队列
self.urlQueue = Queue()
# 解析队列
self.parseQueue = Queue()
def getUrl(self):
'''拼接地址 入队列
'''
for page in range(10):
params = {
'page': str(page),
'categoryId': '10',
'pageSize': '30'
}
# 编码 拼接 入队列
params = urllib.parse.urlencode(params)
url = self.baseurl + params
self.urlQueue.put(url)
def getHtml(self):
'''发送请求 把html给解析队列
'''
while not self.urlQueue.empty():
url = self.urlQueue.get()
res =requests.get(url, headers=self.headers)
res.encoding = 'utf-8'
html = res.text
self.parseQueue.put(html)
def parseHtml(self):
'''提取
'''
while not self.parseQueue.empty():
html = self.parseQueue.get()
hList = json.loads(html)['data']
# hList [{},{}]
for h in hList:
name = h['displayName']
d = {'应用名称': name, '应用链接': 'http://app.mi.com/details?id='+h['packageName']}
with open('xiaomiAPP.json', 'a') as f:
f.write(str(d) + '\n')
def workOn(self):
self.getUrl()
t1List = []
t2List = []
# 采集线程
for i in range(3):
t = Thread(target=self.getHtml)
t1List.append(t)
t.start()
# 回收线程
for i in t1List:
i.join()
# 解析
for i in range(3):
t = Thread(target=self.parseHtml)
t2List.append(t)
t.start()
for i in t2List:
i.join()
if __name__ == "__main__":
begin = time.time()
spider = MiSpider()
spider.workOn()
end = time.time()
print('sucessful within ___%.2f___' % (end-begin))
博主个人能力有限,错误在所难免.
如发现错误请不要吝啬,发邮件给博主更正内容,在此提前鸣谢.
Email: JentChang@163.com (来信请注明文章标题,如果附带链接就更方便了)
你也可以在下方的留言板留下你宝贵的意见.



