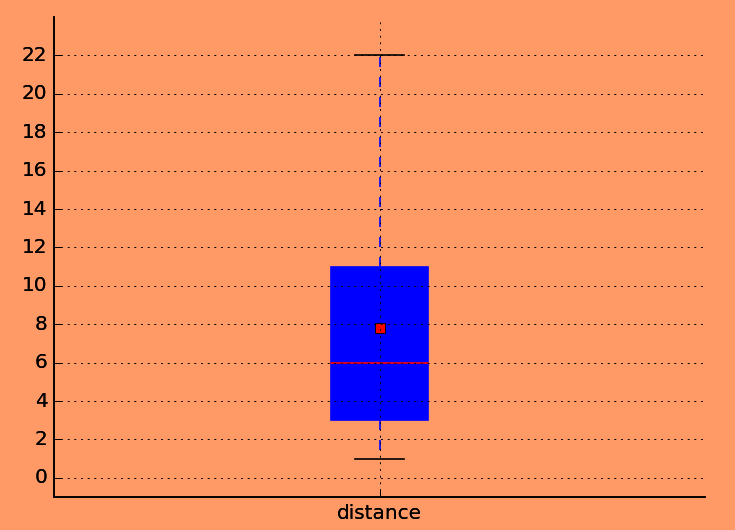
茎叶图
将数的大小基本不变或变化不大的位作为一个主干(茎),将变化大的位的数作为分枝(叶),列在主干的后面,这样就可以清楚地看到每个主干后面的几个数,每个数具体是多少。
它可以直观的表现出数据的分布情况,而且把每个数字都准确的记录下来(没有原始数据信息的损失),快速的计算均值,中位数,众数.
队员得分的数据
0, 0, 2, 4, 7, 7, 9, 11, 11, 13, 18, 20, 22, 22, 23, 25, 26, 26, 26, 28, 29, 31, 33, 35, 36, 41
茎叶图
0 | 0 0 2 4 7 7 9
1 | 1 1 3 8
2 | 0 2 2 3 5 6 6 6 8 9
3 | 1 3 5 6
4 | 1
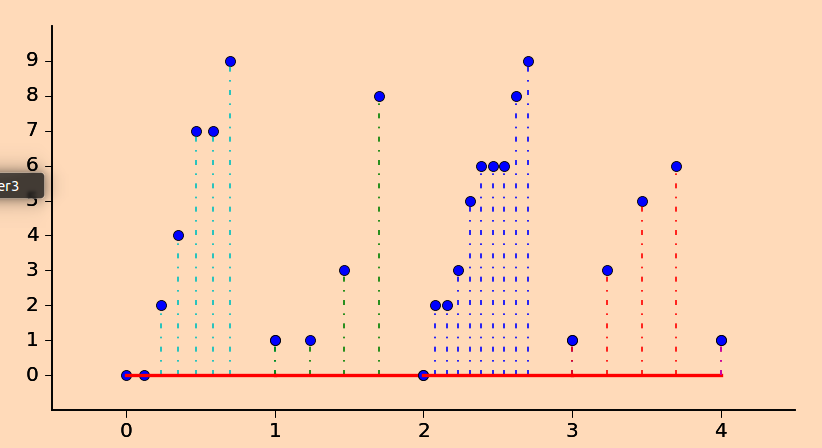
茎叶图的好处是可以很快的得出每个区间的数量,以及很快的看出数据集中在哪里.
这里并不是一个正经的茎叶图,我利用
stem画出了我的想法,你也可以绘制你自己的茎叶图.在这里你会发现2-3数据比较密集,对的,这说明数据集中在20多(中位数可能分布在这附近),也可以通过水平相邻的等高点的分布很快发现众数等等,其实可视化重要的是一眼能看出不同数据之间的差异和关系,可以发现它的特性,而不需要取具体的计算.
利用pyhton绘图
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.axisartist.axislines import SubplotZero
data = [
0, 0, 2, 4, 7, 7, 9, 11, 11, 13, 18, 20, 22,
22, 23, 25, 26, 26, 26, 28, 29, 31, 33, 35, 36, 41
]
x = []
y = []
a, b, c, d, f = 0, 0, 0, 0, 0
for i in data:
if i < 10:
a += 1
elif i < 20:
b += 1
elif i < 30:
c += 1
elif i < 40:
d += 1
elif i < 50:
f += 1
y.append(i % 10)
x = np.zeros((len(data)))
x[0:a] = np.linspace(0, 0.7, a)
x[a:a+b] = np.linspace(1, 1.7, b)
x[a+b:a+b+c] = np.linspace(2, 2.7, c)
x[a+b+c:a+b+c+d] = np.linspace(3, 3.7, d)
x[a+b+c+d:a+b+c+d+f] = np.linspace(4, 4.7, f)
xticks = np.arange(0, 5, 1)
yticks = np.arange(0, 10, 1)
fig = plt.figure(figsize=(8, 4), dpi=120, facecolor='#FFDAB9', edgecolor='c')
ax1 = SubplotZero(fig, 1, 1, 1, axisbg='#FFDAB9')
fig.add_subplot(ax1)
# ax1.grid(True, color='k', linestyle='-.')
ax1.axis['right', 'top'].set_visible(False)
ax1.set_xticks(xticks)
ax1.set_yticks(yticks)
ax1.set_xlim(-0.5, 4.5)
ax1.set_ylim(-1, 10)
for axis in ax1.axis.values():
axis.major_ticks.set_tick_out(True) # 标签全部在外部
markerline, stemlines, baselines = plt.stem(x[0:a+1], y[0:a+1], 'c-.')
plt.setp(baselines, color='r', linewidth=2)
markerline, stemlines, baselines = plt.stem(x[a:a+b+1], y[a:a+b+1], 'g-.')
plt.setp(baselines, color='r', linewidth=2)
markerline, stemlines, baselines = plt.stem(x[a+b:a+b+c+1], y[a+b:a+b+c+1], 'b-.')
plt.setp(baselines, color='r', linewidth=2)
markerline, stemlines, baselines = plt.stem(x[a+b+c:a+b+c+d+1], y[a+b+c:a+b+c+d+1], 'r-.')
plt.setp(baselines, color='r', linewidth=2)
markerline, stemlines, baselines = plt.stem(x[a+b+c+d:a+b+c+d+f], y[a+b+c+d:a+b+c+d+f], 'm-.')
plt.setp(baselines, color='r', linewidth=2)
plt.plot((0,0), (4,4), 'r-', linewidth=2)
plt.show()
统计的内容中会经常用到matplotlib,如果你对它感兴趣,可以关注后期的
Machine Learning中matplotlib内容.
当然,那里的例子不像这样的繁琐,并且会要你想要的一些参数的说明
博主个人能力有限,错误在所难免.
如发现错误请不要吝啬,发邮件给博主更正内容,在此提前鸣谢.
Email: JentChang@163.com (来信请注明文章标题,如果附带链接就更方便了)
你也可以在下方的留言板留下你宝贵的意见.