误导人的线形图
消费者偏好数据
表中给出受访者中偏爱美味可乐(激动汽水,没有偏好)的人数百分比
| years | Prefer Yummy Cola | Prefer Thril Soda | No preference |
|---|---|---|---|
| 2006 | 80% | 12% | 8% |
| 2007 | 76% | 19% | 5% |
| 2008 | 77% | 19% | 4% |
| 2009 | 73% | 20% | 7% |
| 2010 | 73% | 21% | 6% |
| 2011 | 68% | 25% | 7% |
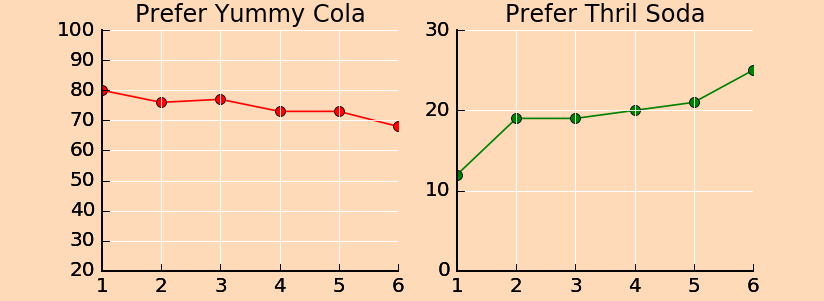
从图中我们看到,里面的数据是正确的(和表中是对应的)
喜爱美味可乐的人比例在下降,喜爱激动汽水人数占比在增加
但是我们并不能给出变化幅度的结论,而且即使喜爱美味可乐的人占比下降,其实喜爱激动汽水的人数占比还是远远跟不上的,至少按照这样还是一个长远的过程.
我觉得我们需要一个正确的绘图来表达两个的对比
他们需要相同的坐标中比较
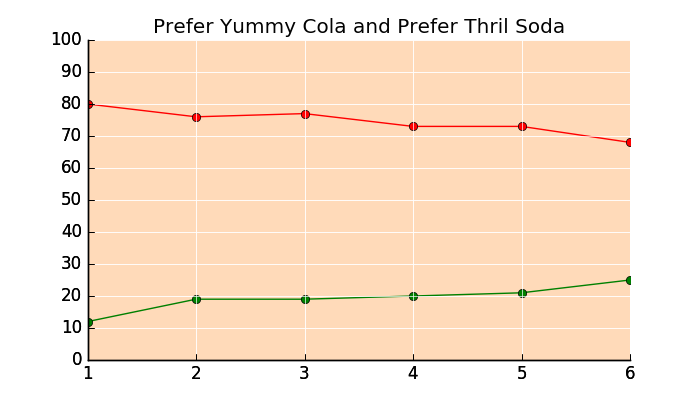
利用pyhton绘制线性图
误导人的线形图程序
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.axisartist.axislines import SubplotZero
# 设置图窗口1
fig = plt.figure(figsize=(7, 2), dpi=120, facecolor='#FFDAB9', edgecolor='c')
ax1 = SubplotZero(fig, 1, 2, 1, axisbg='#FFDAB9')
fig.add_subplot(ax1)
ax1.grid(True, color='w', linestyle='-')
ax1.axis['right', 'top'].set_visible(False)
# 设置窗口2
ax2 = SubplotZero(fig, 1, 2, 2, axisbg='#FFDAB9')
fig.add_subplot(ax2)
ax2.grid(True, color='w', linestyle='-')
ax2.axis['right', 'top'].set_visible(False)
# 创建数据
prefer = ['Prefer Yummy Cola', 'Prefer Thril Soda', 'No preference']
years = ['2006', '2007', '2008', '2009', '2010', '2011']
years_x = np.arange(1, len(years)+1)
prefer_cola = [80, 76, 77, 73, 73, 68]
prefer_soda = [12, 19, 19, 20, 21, 25]
y_cola = np.arange(20, 110, 10)
y_soda = np.arange(0, 40, 10)
# 画图
ax1.plot(years_x, prefer_cola, 'r-o')
ax1.set_xticks(years_x, years)
ax1.set_yticks(y_cola)
ax1.set_title(prefer[0])
ax2.plot(years_x, prefer_soda, 'g-o')
ax2.set_xticks(years_x, years)
ax2.set_yticks(y_soda)
ax2.set_title(prefer[1])
plt.show()
正确的线形绘图程序
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.axisartist.axislines import SubplotZero
# 设置图窗口1
fig = plt.figure(figsize=(7, 4), dpi=120, facecolor='#FFDAB9', edgecolor='c')
ax1 = SubplotZero(fig, 1, 1, 1, axisbg='#FFDAB9')
fig.add_subplot(ax1)
ax1.grid(True, color='w', linestyle='-')
ax1.axis['right', 'top'].set_visible(False)
# 创建数据
prefer = ['Prefer Yummy Cola', 'Prefer Thril Soda', 'No preference']
years = ['2006', '2007', '2008', '2009', '2010', '2011']
years_x = np.arange(1, len(years)+1)
prefer_cola = [80, 76, 77, 73, 73, 68]
prefer_soda = [12, 19, 19, 20, 21, 25]
y_cola = np.arange(0, 110, 10)
# 画图
ax1.plot(years_x, prefer_cola, 'r-o')
ax1.plot(years_x, prefer_soda, 'g-o')
ax1.set_xticks(years_x, years)
ax1.set_yticks(y_cola)
ax1.set_title('Prefer Yummy Cola and Prefer Thril Soda')
plt.show()
由于博文标题在图片上的颜色影响,代码中添加了背景的设置,如果觉得过于繁琐,可以参照前几节的matplotlib命令,或者参考后期的
Machine Learning中matplotlib内容.
博主个人能力有限,错误在所难免.
如发现错误请不要吝啬,发邮件给博主更正内容,在此提前鸣谢.
Email: JentChang@163.com (来信请注明文章标题,如果附带链接就更方便了)